
CCINP Informatique PSI 2019
| Thème de l'épreuve | Intelligence Artificielle - Application en médecine |
| Principaux outils utilisés | requêtes SQL, tableaux, tri, probabilités, statistiques, bibliothèque numpy |
| Mots clefs | intelligence artificielle, hernie discale, spondylolisthésis, méthode KNN, plus proches voisins, méthode naïve bayésienne, matrice de confusion, prédiction, apprentissage supervisé, apprentissage automatique |
Corrigé
: 👈 gratuite pour tous les corrigés si tu crées un compte👈 l'accès aux indications de tous les corrigés ne coûte que 5 € ⬅ clique ici
👈 gratuite pour tous les corrigés si tu crées un compte
- - - - - - - - - - - - - - - - - - - - -
Énoncé complet
(télécharger le PDF)







Rapport du jury
(télécharger le PDF)


Énoncé obtenu par reconnaissance optique des caractères
SESSION 2019 C PSIINO7
CONCOURS
COMMUN
INP
ÉPREUVE SPÉCIFIQUE - FILIÈRE PSI
INFORMATIQUE
Vendredi3 mai:8h-11h
N.B. : le candidat attachera la plus grande importance à la clarté, à la
précision et à la concision de
la rédaction. Si un candidat est amené à repérer ce qui peut lui sembler être
une erreur dénoncé, il le
signalera sur Sa copie et devra poursuivre sa composition en expliquant les
raisons des initiatives
qu'il a été amené à prendre.
Les calculatrices sont interdites
Le sujet est composé de trois parties indépendantes.
L'épreuve est à traiter en langage Python, sauf les questions sur les bases de
données qui seront
traitées en langage SQL. La syntaxe de Python est rappelée en Annexe, page 12.
Les différents algorithmes doivent être rendus dans leur forme définitive sur
la copie en respectant les
éléments de syntaxe du langage (les brouillons ne sont pas acceptés).
Il est demandé au candidat de bien vouloir rédiger ses réponses en précisant
bien le numéro de la
question traitée et, si possible, dans l'ordre des questions. Bien que
largement indépendante, la
partie [IT fait appel aux données et à la définition de fonctions définies dans
la partie IT.
La réponse ne doit pas se cantonner à la rédaction de l'algorithme sans
explication, les programmes
doivent être expliqués et commentés.
Sujet : page 1 à page 11
Annexe : page 12
1/12
Intelligence Artificielle - Application en médecine
Partie I - Présentation
L'Intelhigence Artifñcielle est de plus en plus utilisée dans de nombreux
domaines divers et variés.
Les techniques d'apprentissage machine, qui permettent à un logiciel
d'apprendre automatiquement à
partir de données au lieu d'être explicitement programmé, fournissent des
résultats impressionnants.
Les applications sont nombreuses dans la reconnaissance d'image, la
compréhension de la parole ou
de textes, dans l'assistance à la décision, dans la classification de données,
dans la robotique.
L'Intellhigence Artiñcielle progresse également dans le domaine de la santé. Le
logiciel Watson déve-
loppé par IBM peut analyser les données d'un patient : ses symptômes, ses
consultations médicales,
ses antécédents familiaux, ses données comportementales, ses résultats
d'examen, etc. Il établit alors
une prévision de diagnostic le plus vraisemblable et propose des options de
traitement en s'appuyant
sur une base de données établie sur un grand nombre de patients.
Objectif
L'objectif du travail proposé est de découvrir quelques techniques
d'Intelligence Artificielle en
s'appuyant sur un problème médical. À partir d'une base de données comportant
des propriétés
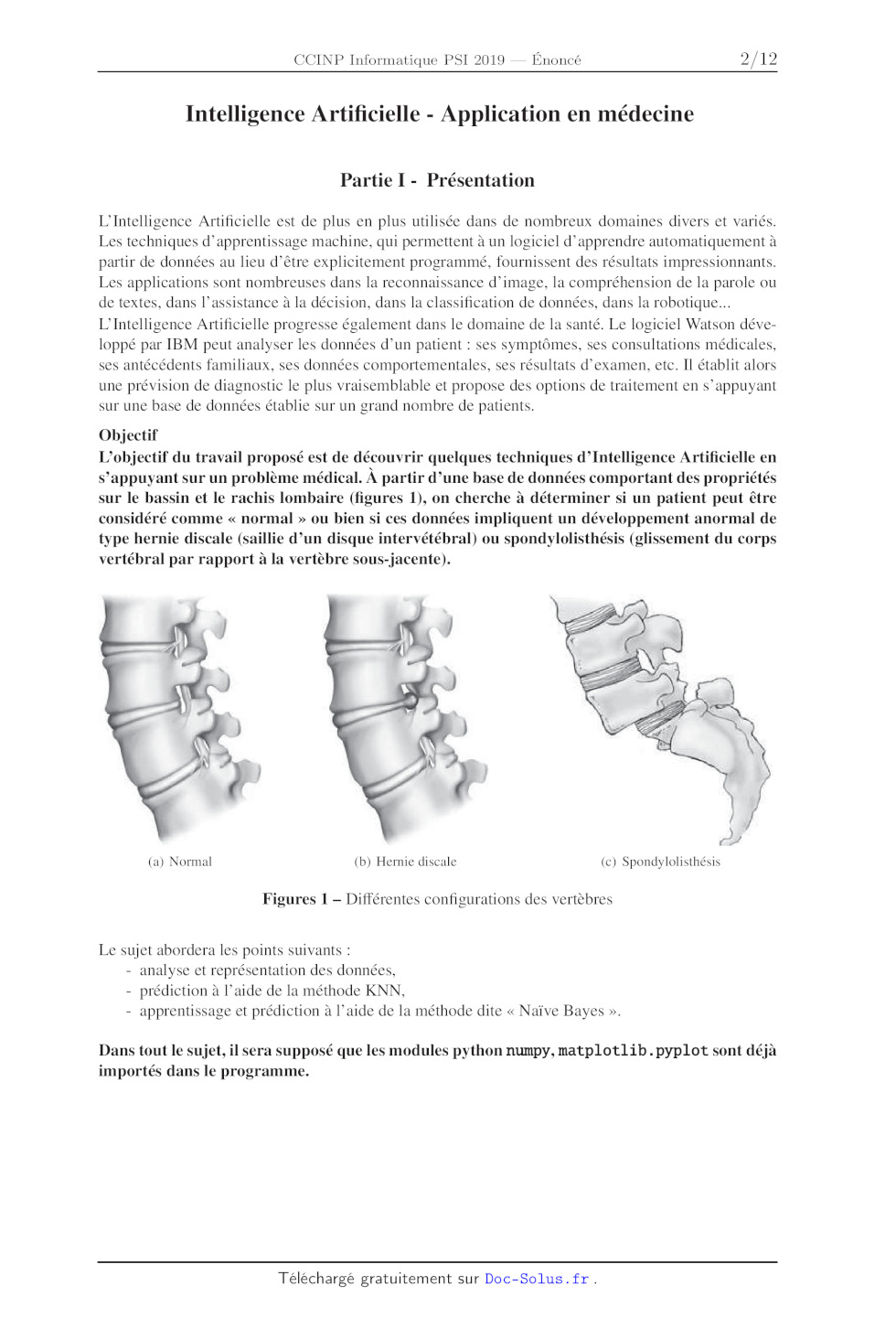
sur le bassin et le rachis lombaire (figures 1), on cherche à déterminer si un
patient peut être
considéré comme « normal » ou bien si ces données impliquent un développement
anormal de
type hernie discale (saillie d'un disque intervétébral) ou spondylolisthésis
(glissement du corps
vertébral par rapport à la vertèbre sous-jacente).
(a) Normal (b) Hernie discale (c) Spondylolisthésis
Figures 1 -- Différentes configurations des vertèbres
Le sujet abordera les points suivants :
- analyse et représentation des données,
- prédiction à l'aide de la méthode KNN,
- apprentissage et prédiction à l'aide de la méthode dite « Naïve Bayes ».
Dans tout le sujet, il sera supposé que les modules python
numpy,matplotlib.pyplot sont déjà
importés dans le programme.
2/12
Partie II - Analyse des données
La base de données médicale contient des informations administratives sur les
patients et des infor-
mations médicales. Pour simplifier le problème, on considère deux tables :
PATIENT et MEDICAL.
La table PATIENT contient les attributs suivants : ( PATIENT | { MEDICAL |
- id : identifiant d'un individu (entier), clé primaire ;
- nom : nom du patient (chaîne de caractères) ; id id
- prenom : prénom du patient (chaîne de caractères) ; renom a
- adresse : adresse du patient (chaîne de caractères) ; adresse h
- email : (chaîne de caractères) ; email idpatient
- naissance : année de naissance (entier). | naissance ) __ etat J
La table MEDICAL contient les attributs suivants :
- 1d : identifiant d'un ensemble de propriétés médicales (entier), clé primaire
;
datal : donnée (flottant) ;
data? : donnée (flottant) ;
9
idpatient : identifiant du patient représenté par l'attribut 1d de la table
PATIENT (entier) ;
etat : description de l'état du patient (chaîne de caractères).
Les attributs datal, data2.. sont des données relatives à l'analyse médicale
souhaitée (dans notre cas
des données biomécaniques). L'attribut « etat » permet d'affecter un label à un
ensemble de données
médicales : « normal », « hernie discale », « spondylolisthésis ».
Q1. Écrire une requête SQL permettant d'extraire les identifiants des patients
ayant une « hernie
discale ».
Q2. Écrire une requête SQL permettant d'extraire les noms et prénoms des
patients atteints de
« Spondylolisthésis ».
Q3. Écrire une requête SQL permettant d'extraire chaque état et le nombre de
patients pour chaque
état.
Une telle base de données permet donc de faire de nombreuses recherches
intéressantes pour essayer
de trouver des liens entre les données des patients et une maladie. Cependant,
compte-tenu du nombre
d'informations disponibles, 1l est nécessaire de mettre en place des outils
pour aider à la classification
de nouveaux patients. C'est l'objet des algorithmes d'Intelligence Artificielle
développés dans la suite.
Pour l'étude qui va suivre, on extrait de la base de données les attributs
biomécaniques de chaque
patient que l'on stocke dans un tableau de réels (codés sur 32 bits) à N lignes
(nombre de patients)
et n colonnes (nombre d'attributs égal à 6 dans notre exemple). On nomme data
ce tableau. L'état
de santé est stocké dans un vecteur de taille N contenant des valeurs entières
(codées sur 8 bits)
correspondant aux différents états pris en compte (0 : normal, 1 : hernie
discale, 2 : spondylolisthésis).
On le nomme : etat.
Les variables data et etat sont stockées dans des objets de type array de la
bibliothèque Numpy.
Des rappels quant à l'utilisation de ce module Python sont donnés dans l'
Annexe, page 12.
Q4. Citer un intérêt d'utiliser la bibliothèque de calcul numérique Numpy quand
les tableaux sont
de grande taille.
Q5. Déterminer la quantité de mémoire totale en Mo (1 Mo = 1 000 000 octets)
nécessaire pour
stocker le tableau et le vecteur des données s1 N = 100 000. On supposera que
les données
sont représentées en suivant la norme usuelle IEEE 754.
3/12
Les 6 attributs considérés dans notre exemple (les n colonnes du tableau) sont
définis ci-après
- angle d'incidence du bassin en ';
- angle d'orientation du bassin en ";
- angle de lordose lombaire en ";
- pente du sacrum en ";
- rayon du bassin en mm;
- distance algébrique de glissement de spondylolisthésis en mm.
Les labels de ces attributs sont stockés dans une liste nommée :
label_attributs
'pente_sacrum',
['incidence_bassin',
'rayon_bassin',
'orientation_bassin',
'glissement_spon'|.
Le tableau suivant montre les premières valeurs du tableau data.
'angle_lordose',
incidence bassin
orientation_ bassin
angle_lordose
pente_sacrum
rayon_bassin
glissement_spon
63,03
22,55
39,61
40,48
98,67
-- 0,25
39,06
10,06
25,02
29,0
114,41
4,56
68,83
22,22
50,09
46,61
105,99
-- 3,53
69,3
24,65
44,31
44,64
101,87
11,21
49,71
9,65
28,32
40,06
108,17
7,92
40,25
13,92
25,12
26,33
130,33
2,23
48,26
16,42
36,33
31,84
94,88
28,34
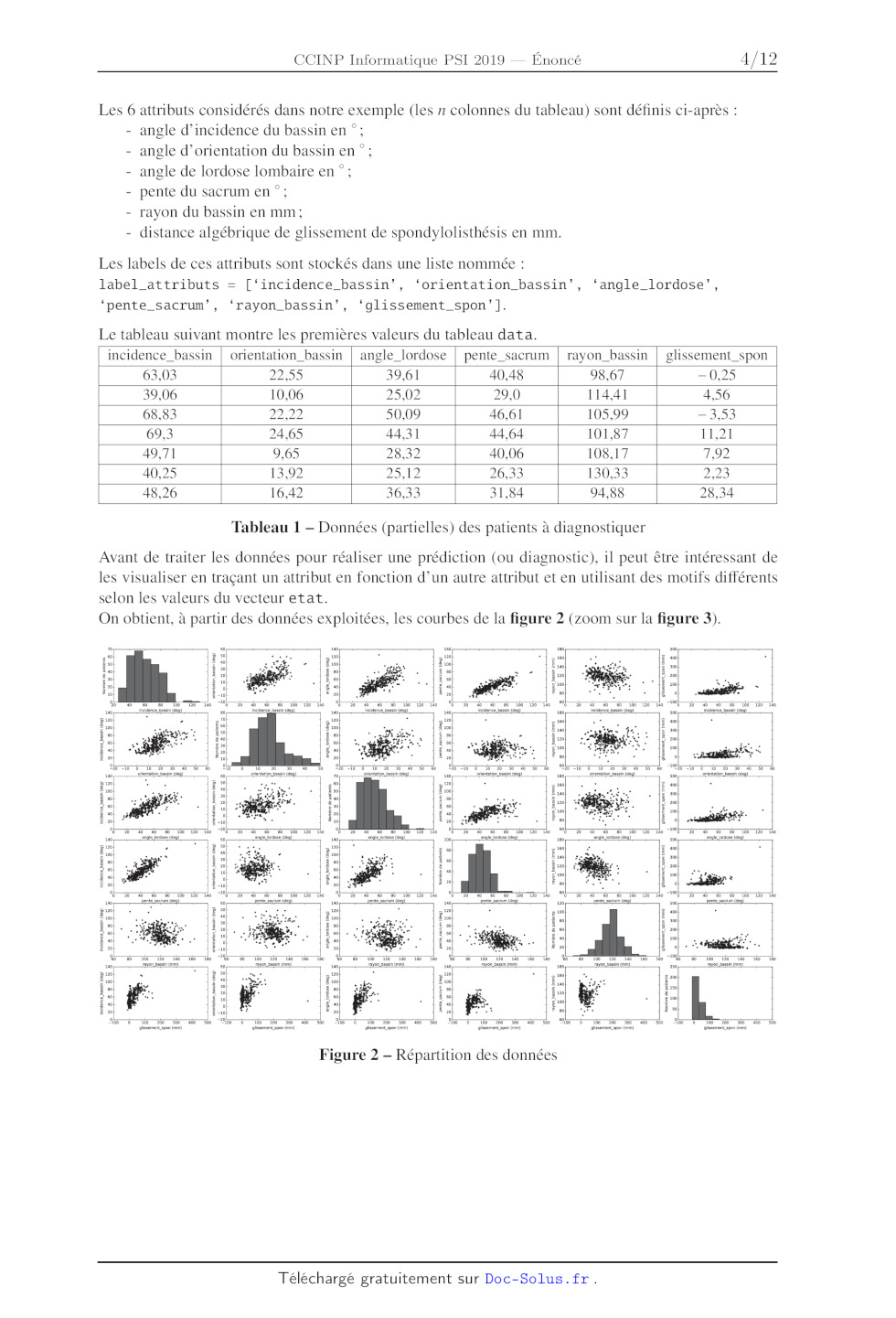
Tableau 1 -- Données (partielles) des patients à diagnostiquer
Avant de traiter les données pour réaliser une prédiction (ou diagnostic), 1l
peut être intéressant de
les visualiser en traçant un attribut en fonction d'un autre attribut et en
utilisant des motifs différents
selon les valeurs du vecteur etat.
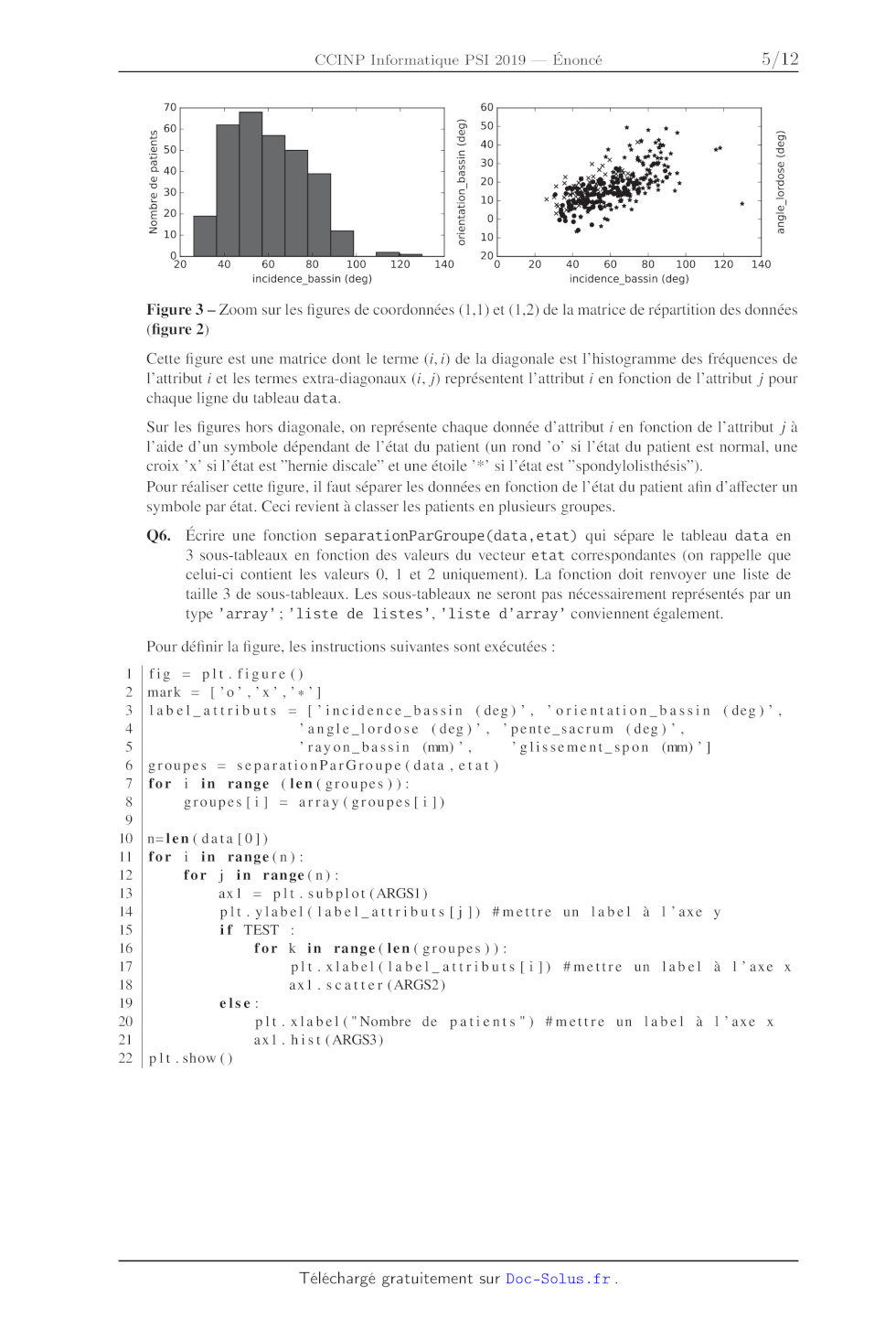
On obtient, à partir des données exploitées, les courbes de la figure 2 (zoom
sur la figure 3).
140 140 180 00
18 5 120F 5 120 * = 160! * JE 400!
£ & 100! 5 100! Ë E
£ ? © £ 140! 15 300}
" 2 80} E 80F £ a
" 8 5 % 120 1% 200|
15 5 60! g 60! $ * |S *
2 1 1 L * 1 " *
É 2 40! # aol 5 100 £ 100 + tt «
EUR £ a ü à À
L le 5 20} 3 20} = 80} 15 of x se
oO *
0 L 0 L 0 L L L 60 L L L L L L 00 L L L L L L
2 0 100 140 20 8 0 120 140 20 0 0 100 120 140 20 40 60 80 100 120 140 20 40 60
80 100 120 140
20 incidence_bassin (deg) incidence_bassin (deg) 40 incidence_bassin (deg) 40
incidence_bassin (deg) 180 incidence_bassin (deg) c00 incidence_bassin (deg)
*
5 120 - # 5 220} 3 120} & 160 ,* £ 400!
D EUR © © *
g 100! + * À È £ 100! Z 100E £ 140! "°° 44° £ 300!
'ü Er Li * sg (a £ £ « % ge * A * + °
ñ 80 ,% se v 8 50) So " à 120 "Te ee * % 200
2 * ++ D D Oo * # n F e x , ol
l L # * = L © L * e © * k
g 60 ,*, Re £ s, © 5, 50 ... Sibiiehss 00 Fee SR ee ee [5 00 . de,
& 40. e s É 2 40! £ 40 1" Ma ae S F Eu ee * + Ê [ # SE *
Z je * S PB £ En ve * 3 Lorrt tn ÿ AM FR
y z = L * = E
E 20} 5 20} 2 20 LE x + 80 7, * 5 0 ed x *
0 L L L L L 0 0 L L L L 60 L L L L L L L 100 L L L L L L L
--20 --10 0 10 20 30 40 10 --2 1 --20 --10 10 20 0 50 60 --20 --10 0 10 20 30
40 50 60 --20 --10 1 0 0 50 60
140 orientation bassin (deg) orientation bassin (deg) 70 orientation bassin
(deg) 140 orientation bassin (deg) 180 c00 orientation bassin (deg)
* =
SG 120} . 19 +, ++ ny 604 = 120 160 JE 400! *
$ £ és a = ë E Ë
7 100 "à *. EUR "+ + D 5 50! D 100! £ =
£ « me £ de a+ 5 £ È 140! x 15 300!
ë 80} «+ Fran 8 Fe de CEE 8 40} E 80! + us £ 2
S è ee, 8, ARS « 2 5 + met ® 120 4/71 200!
w 601 #% A ls se" 5 30! B 60! * mé) ë È "
Y 2 * = 1 # +
& L x . # * * 2 L 2 L e D 5 1007 1£ 100 * # de tx
5%) x è re, 520 sl tee ë ù RTE
£ 20. 15 ° Z 10} 8 20 Xe + = 80. 15 0f *x* e** e
0 L L L L L 0 0 L L L 60 L L 100 L L L
20 4 0 1 0 40 60 80 10 140 40 80 00 120 20 0 60 80 10 120 140 20 1 120 140 20
40 60 80 1 120 140
140 angle lordose (deg) angle Jordose (deg) 140 100 angle_lordose (deg) 180
angle lordose (deg) e00 angle Jordose (deg)
g 120; # 15 * "+ 5 120F y 160! " | E 400!
© 100! £ te * & 100! 5 Ê £
£ * EUR x et ©? En £ 140! l< 300} ü | ñ $ us oe | S c S ä 80 ® Rx " g 80 à a $ 8, xx ge * 8 2 & 120 * 1% 200} a! 60! s Ne + 5 60| v 4 ; & "+ + Ô _ * ! = * * e 5 * 5 £ 100! J£ 100! gx ÿ 4! 5 EU 3 40! Ë $ È , d her © 8 20! È + 8 ol Z Ê go! * 12 0! ee TT Oo 0 L L L L L L L 0 L L L L L L 60 L L L L L L 100 L L L L L L 20 40 60 80 100 0 40 60 80 100 140 20 40 60 80 100 120 140 20 40 60 80 100 120 4 20 40 60 80 100 120 140 20 40 60 80 100 120 140 20 pente _sacrum (deg) 140 pente_sacrum (deg) 140 pente _sacrum (deg) 150 pente _sacrum (deg) e00 pente _sacrum (deg) G 120 15 = 120 = 120 * JE | È ° È Laure 5 5 2 cn Y 100! EUR Font 2 100} " * . £ 100F È JE 300! G u CURE Te vo CA à £ oe © 8 80| 8 RER ® 80} gr us x 5 80 * à g ss * 8, ue » D * 14 * Las » © * + ** $ 1 200 w! 60} £ Lx $ GS 60! « Hs ..° % 60 ri à À & EUR " YU © ce * "© 1 ne ox ° * + Le jo * * L g ü 40. 5 À ° 2 40! De ,° £ 40 te LA: Ê 1£ 100 PT CE È Ë are E ae ë NS ce | 5 ë à EE £ 20 5 * 5 20} x » 2 20} ui + z 15 0 x . 0 L L L L L L 0 L L L L 0 L L L L L 00 L L L L L 60 80 100 120 140 0 100 120 140 180 60 80 100 120 140 160 180 60 80 100 120 140 160 180 80 100 120 140 160 0 60 80 100 120 140 160 180 120 rayon_bassin (mm) rayon_bassin (mm) 140 rayon_bassin (mm) 140 rayon_bassin (mm) 20 rayon_bassin (mm) Den rayon_bassin (mm) SG 120. 15 * - 120 = 120 * 8 * 5 ste 5 S & 160 2 200! x 100F E Sa Z 100F âets £ 100F E 140 re D ê È si a re E L et re 8 150 m 80. a . 80 À E 80! EUR * + & s * $, « $ fes 5 x 8 120 * 2 a! 60} + 5 * 5 60} " 8 60 Ze. ë ® 100! Ê ü w! x * * gl se" c'100! 5 CE ] % Dm 40} + 40 el © La £ D EUR * £ LA 5 "++ A Ps S 50! É 20! L S 20l * a 20! S 80! s* + Z TT oO 0 L L L L L L 0 L L L L L 0 L L L L L 60 L L L L L --100 0 100 200 300 0 100 200 300 500 --100 0 100 200 300 400 500 --100 0 100 200 300 400 500 --100 0 100 200 300 400 500 --100 0 100 200 300 400 500 glissement_spon (mm) glissement_spon (mm) glissement_spon (mm) glissement_spon (mm) glissement_spon (mm) glissement_spon (mm) Figure 2 -- Répartition des données 4/12 © © I ON 1 & © D NO DD A mn nm mm mm em em D nm OLD IA 1 À © D = © 70 60 | | y 60 ë 50 | 1 = 50 E | EE 5 uw 30 © 40 © n v 2, 20 1 © = 2 10 }- x TT] Q + OU £ 20 S OL JT o 2 g ë 10 5 10+ J O0 20 l l | l l | 20 40 60 80 100 120 140 0 20 40 60 80 100 120 140 incidence bassin (deg) incidence bassin (deg) Figure 3 -- Zoom sur les figures de coordonnées (1,1) et (1,2) de la matrice de répartition des données (figure 2) Cette figure est une matrice dont le terme (5, i) de la diagonale est l'histogramme des fréquences de l'attribut i et les termes extra-diagonaux (1, j) représentent l'attribut z en fonction de l'attribut j pour chaque ligne du tableau data. Sur les figures hors diagonale, on représente chaque donnée d'attribut : en fonction de l'attribut 7 à l'aide d'un symbole dépendant de l'état du patient (un rond 'o° si l'état du patient est normal, une croix 'X° Si l'état est hernie discale" et une étoile '*" s1 l'état est "'spondylolisthésis"). Pour réaliser cette figure, 1l faut séparer les données en fonction de l'état du patient afin d'aftecter un symbole par état. Ceci revient à classer les patients en plusieurs groupes. Q6. Écrire une fonction separationParGroupe(data,etat) qui sépare le tableau data en 3 sous-tableaux en fonction des valeurs du vecteur etat correspondantes (on rappelle que celui-c1 contient les valeurs 0, 1 et 2 uniquement). La fonction doit renvoyer une liste de taille 3 de sous-tableaux. Les sous-tableaux ne seront pas nécessairement représentés par un type array"; liste de listes', 'liste d'array" conviennent également. Pour définir la figure, les instructions suivantes sont exécutées : fig = plt.figure() mark = ['0°,°x",'*x°] label_attributs = ['incidence bassin (deg)', 'orientation_bassin (deg)', "angle _lordose (deg)', 'pente _ sacrum (deg)', "rayon_bassin (mm), glissement _spon (mm)"'| groupes = separationParGroupe(data ,etat) for 1 in range (len(groupes)): groupes{1] = array(groupes{i1l]) n=len(data[0|) for 1 in range(n): for j in range(n): axil = plt.subplot(ARGSI) pit.ylabel(label_attributs[j]]) #mettre un label à 1'axe y if TEST for k in rangel(len (groupes) ): pit.xlabel(label_attributs[1]) #mettre un label à 1'axe x axil.scatter (ARGS2) else : pit.xlabel("Nombre de patients") #mettre un label à l'axe x axil.h1st (ARGS3) pit.show() 5/12 Les instructions précédentes utilisent la fonction separationParGroupe définie à la question Q6, puis les éléments de la liste groupes sont convertis en array afin de pouvoir extraire les colonnes plus facilement. La documentation du module matplotl1b (plt) renseigne sur les arguments des fonctions subplot, scatterethist. jaxl = plt.subplot(a,b,k) Cette instruction permet de sélectionner parmi un tableau de figures de taille a (nombre de lignes), b (nombre de colonnes), la k° en numérotant les sous-figures de 1 à m x n en partant du haut gauche vers le bas droite (en allant de gauche à droite et de haut en bas). jaxl . Scatter(datax , datay , marker=mark![K |) Cette commande permet de tracer sur la sous-figure ax] un nuage de points d'abscisses un vecteur datax et d'ordonnées un vecteur datay avec un symbole à choisir parmi ceux de la liste mark. jaxl.hist(datax) Cette commande permet de tracer un histogramme des données datax sur la sous-figure ax. Q7. Définir les arguments ARGSI, ARGS2, ARGS3 ainsi que la condition TEST définis dans le script précédent permettant d'obtenir la figure 2. QS. Préciser l'utilité des diagrammes de la diagonale ainsi que celle des diagrammes hors diago- nale. Partie IIT - Apprentissage et prédiction III.1 - Méthode KNN La méthode KNN est une méthode d'apprentissage dite supervisée ; les données sont déjà classées par groupes clairement identifiés et on cherche dans quels groupes appartiennent de nouvelles données. Le principe de la méthode est simple. Après avoir calculé la distance euclidienne entre toutes les données connues des patients et les données d'un nouveau patient à classer, on extrait les K données connues les plus proches. L'appartenance du nouveau patient à un groupe est obtenue en cherchant le groupe majoritaire, c'est-à-dire, le groupe qui apparaît être le plus représentatif parmi les K données connues. On note X;, 1 EUR [0, n -- 11], le vecteur colonne : du tableau de données data, c'est-à-dire les valeurs prises par l'attribut : des données des patients déjà classées. On cherche à déterminer à quel groupe appartient un nouveau patient dont les attributs sont représentés par un n-uplet z de valeurs notées (Zo; Lis. Zn-1). Préparation des données Avant de calculer la distance euclidienne, 1l est préférable de normaliser les attributs pour éviter qu'un attribut ait plus de poids par rapport à un autre. On choisit de ramener toutes les valeurs des attributs entre 0 et I. Une technique de normalisation consiste à rechercher pour chaque attribut X le minimum (min(X)) qui est placé à 0 et le maximum (max(X)) qui est placé à 1. On note alors X,,,, un des vecteurs colonne X après normalisation (toutes les valeurs de X,,,, Sont donc comprises entre 0 et 1). 6/12 DO JAN 1 & © D SR D mm © DO IA Li R © D A © \O Q9. Proposer une expression de Xyorm; Un élément du vecteur X,,,n en fonction de l'élément x; du vecteur À correspondant et de min(X) et max(X). Q10. Ecrire une fonction min_max(X) qui retourne les valeurs du minimum et du maximum d'un vecteur À passé en argument. La fonction devra être de complexité linéaire. Q11. Écrire une fonction distance(z, data) qui parcourt les N lignes du tableau data et calcule les distances euclidiennes entre le n-uplet z et chaque n-uplet x du tableau de données connues (x représente une ligne du tableau). La fonction doit renvoyer une liste de taille N contenant les distances entre chaque n-uplet x et le n-uplet z. Détermination des K plus proches voisins Pour déterminer les K plus proches voisins avec K un entier choisi arbitrairement, 1l suffit d'utiliser un algorithme de tri efficace. La liste T à trier est une liste de listes à 2 éléments contenant : - la distance entre le n-uplet à classer et un n-uplet connu (on trie par ordre croissant sur ces valeurs) ; - Ja valeur de l'état correspondant au n-uplet connu. On retient l'algorithme suivant : def tri(T): if len(T) <= l!: return Î else : m = len(T)//2 tmpl = [] for x in range (m): tmpl.append(T[xl]) tmp2 = |] for x in range(m,len(T) ): tmp2.append(T[xl}]) return fct(tri(tmpl),tr1i(tmp2)) def fct(TI,T2): If T1 == |]: Léreeeeeeessseeeee #ligne 1 à compléter Léreeeeeeessseeeee #ligne 2 à compléter If TI[OÏJ[O] < T2[0][0]: return [TI[0O]|+fct(TI[1:],T2) else : Léreeeeeeessseeeee #ligne 3 à compléter Q12. Donner le nom de ce tri ainsi que son intérêt par rapport à un tri par insertion. Préciser un inconvénient du programme proposé par rapport à ce tri. Q13. Préciser les lignes 1 à 3 de la fonction fct pour que l'algorithme de tri soit fonctionnel. 7/12 DO JAN 1 & © D DD en mm mm mm nm nu mm © DO OO IN 1 R © D n © \O © KO © I ON A R © D + bd L'algorithme de la méthode KNN est décrit par la fonction python suivante : def KNN(data ,etat ,Zz,K,nb): #partie Î| T' = {|} dist -- distance(z,data) for 1 in range(len(dist)): T.append([ dist[11],11]) tri(T) #partie 2 select = [0]x+xnb for i in range(K): select[etat[T[1][1]]]+=1 #partie 3 ind = 0 res = select{[0] for Kk in range(l ,nb ): if select[k] > res:
res = selectIKk|
ind = Kk
return ind
K représente le nombre de voisins proches retenus, nb correspond au nombre
d'état (3 dans notre
exemple) et z correspond aux attributs du patient à classer.
Q14. Expliquer ce que font globalement les parties 1 (lignes 3 à 7), 2 (lignes
10 à 12) et 3 (lignes 15
à 21) de l'algorithme. Préciser ce que représentent les variables locales T,
dist, select, ind.
Validation de l'algorithme
Pour tester l'alsorithme, on utilise un jeu de données supplémentaires
normalisées dont l'état des
patients est connu (100 patients). On note datatest ces données et efattest le
vecteur d'état connu
pour ces patients. On applique ensuite l'algorithme sur chaque élément de ce
jeu de données pour une
valeur de K fixée.
On définit la fonction suivante qui renvoie une matrice appelée "'matrice de
confusion".
def test KNN(datatest ,etattest , data ,etat ,K,nb):
etatpredit = {|
for 1 in range(len(datatest)):
res -- KNN(data ,etat , datatest[1],K,nb)
etatpredit.append(res)
mat = np.zeros((nb,nb))
for 1 in range(len(etattest)):
mat[etattest[1],etatpredit[1]] += Î
return mat
23 4 7
On obtient pour K = 8 la matrice suivante :| 7 IT
5 2 40
8/12
Q15. Indiquer l'information apportée par la diagonale de la matrice. Exploiter
les valeurs de la
première ligne de cette matrice en expliquant les informations que l'on peut en
tirer. Faire de
même avec la première colonne. En déduire à quoi sert cette matrice.
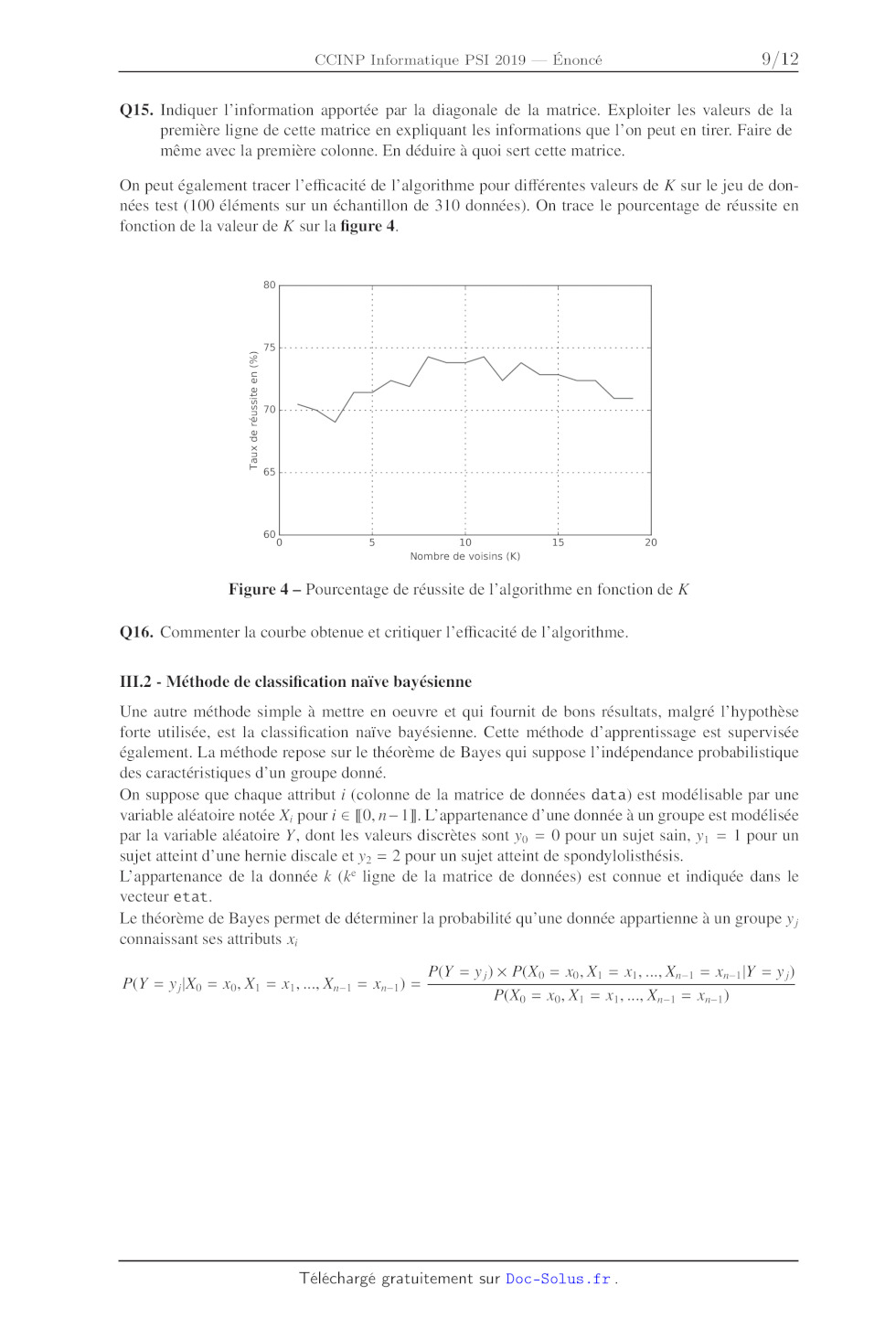
On peut également tracer l'efficacité de l'algorithme pour différentes valeurs
de K sur le jeu de don-
nées test (100 éléments sur un échantillon de 310 données). On trace le
pourcentage de réussite en
fonction de la valeur de K sur la figure 4.
80
Taux de réussite en (%)
65/................ Le Li D
60
0
Nombre de voisins (K)
Figure 4 -- Pourcentage de réussite de l'algorithme en fonction de K
Q16. Commenter la courbe obtenue et critiquer l'efficacité de l'algorithme.
IIL.2 - Méthode de classification naïve bayésienne
Une autre méthode simple à mettre en oeuvre et qui fournit de bons résultats,
malgré l'hypothèse
forte utilisée, est la classification naïve bayésienne. Cette méthode
d'apprentissage est supervisée
également. La méthode repose sur le théorème de Bayes qui suppose
l'indépendance probabilistique
des caractéristiques d'un groupe donné.
On suppose que chaque attribut : (colonne de la matrice de données data) est
modélisable par une
variable aléatoire notée X'; pour i EUR [0,n--11]. L'appartenance d'une donnée
à un groupe est modélisée
par la variable aléatoire Y, dont les valeurs discrètes sont y, = 0 pour un
sujet sain, y, = 1 pour un
sujet atteint d'une hernie discale et y; = 2 pour un sujet atteint de
spondylolisthésis.
L'appartenance de la donnée k& (k° ligne de la matrice de données) est connue
et indiquée dans Île
vecteur etat.
Le théorème de Bayes permet de déterminer la probabilité qu'une donnée
appartienne à un groupe y;
connaissant ses attributs x;
PO = y;) X P(Xo = x0, À = X1, ., À ny = Xn-1|Y = y;)
PT = yifXo = x0, À = X1,., À] = Xn-1) =
I PXo = Xo, À = X1, ., À] = Xn-1)
9/12
= PO = y;lXo = xo, Xi = X1,....., Xn-1 = Xh-1) est la probabilité d'appartenir
au groupe y; sachant
que les diftérentes variables aléatoires X; prennent respectivement les valeurs
x;,
- P(Y = y;) est la probabilité d'appartenir au groupe y;
- P(Xo = xo, À = x1,..., X 51 = Xn1lY = y;) est la probabilité que les
différentes variables
aléatoires X; prennent respectivement les valeurs x; sachant que la donnée
appartient au groupe
j»
- P(Xo = x, Xi = Xi, Àn_1 = Xh_1) est la probabilité que les différentes
variables aléatoires X;
prennent respectivement les valeurs x;.
L'hypothèse naïve bayésienne suppose que tous les attributs sont indépendants
et donc que :
P(X6 = Xo, Xi = Xi, .., Xp = Xn-1|Y = y;) = | [Pr = xiY = y;).
Comme le dénominateur P(X5 = xo, Xi = X1,....., Xy_1 = Xn_1) est indépendant du
groupe considéré et
donc constant, on ne considère que le numérateur :
PO = y;) X P(Xo = %0, À = Xi, Xp = Xn-1|Y = yj).
Pour déterminer le groupe le plus probable auquel appartient une donnée z à
classer, représentée par
le n-uplet (Zo, Z1, ....., Z-1), On choisit la probabilité maximale P(Y = y;) x
IE P(X; = z|Y = y;) parmi
i
les j groupes.
Des lois de probabilités diverses sont utilisées pour estimer P(X; = z;|Y =
y;); nous utiliserons une
loi de distribution gaussienne.
Apprentissage
La première étape consiste à séparer les données selon les groupes auxquels
elles appartiennent. On
réutilise pour cela la fonction separationParGroupe(data,etat) définie à la
question Q6.
Pour calculer la probabilité conditionnelle P(X; = z;|Y = y;) d'une donnée z
représentée par le n-uplet
(Zo, Z1, .. Zn_1), On utilise une distribution gaussienne de la forme
Ï exp - (Z = |
Er 207,
2
OÙ Hx,y, ets, y, SOnt la moyenne et la variance de la variable aléatoire X;,
estimées à partir des valeurs
d'attribut des données de la i-ième colonne du tableau data pour le groupe
correspondant à y;.
Dia > DER Gin)
n n
Q17. Ecrire deux fonctions de complexité linéaire moyenne(x) et variance(x)
permettant de ren-
voyer la moyenne et la variance d'un vecteur x de dimension quelconque.
P(Xi = zilY = y;) =
On rappelle que, pour un vecteur x de dimension n, u =
Q18. Proposer une fonction synthese(data,etat) qui renvoie une liste composée
de doublets
[moyenne, variance] pour chaque attribut de la matrice data en les regroupant
selon les valeurs
du vecteur etat :
[LU x vo » © x0,0 [x vos x vod ..... [Uxs vos xs 50
[LU xo y: , © roy [x y, , x vd ...... [Us y, , xs y 1:
LU xo y » © 10,2 d [x y © xd ...... [Us y» © 5,32 1].
10/12
Cette fonction appliquée au tableau data complet (non normalisé) renvoie une
liste qui contient les
valeurs suivantes :
XI X2 X3 X4 X5 X6
etat=0 [51.68, 12.3] 112.82, 6.74] | [43.54, 12.29] | [38.86, 9.57] 1123.89,
8.96] [2.18, 6.27]
etat=Î| 147.63, 10.6] 117.39, 6.95] 135.46, 9.68 | [30.23, 7.49] 1116.47, 9.27]
[2.48, 5.48]
etat=2 || [71.51, 15.05] | [20.74, 11.46] | [64.11, 16.34] | [50.76, 12.27] |
[114.51, 15.52] | [S1.89, 39.97]
Prédiction
On considère pour la deuxième étape une donnée z à classer représentée par le
n-uplet (20, Z1, ......, Zn_1).
Pour réaliser la prédiction, 1l faut tout d'abord calculer la probabilité
d'appartenance à un groupe
selon la loi gaussienne choisie P(X; = z;|YY = y;) en fonction de l'attribut
considéré, puis multiplier
ces probabilités pour un même groupe y; pour obtenir
ELA EN)
Q19. Écrire une fonction gaussienne(a, moy, v) qui calcule la probabilité selon
une loi gaussienne
de moyenne moy et de variance v pour un élément a de KR.
Q20.
Déduire de la description de l'algorithme de classification naïve bayésienne
une fonction
probabiliteGroupe(z,data,etat) prenant en argument le vecteur z qui contient le
n-uplet de la donnée z, le tableau des données connues data et le vecteur
d'appartenance à
un groupe de chacune de ces données etat. Cette fonction renvoie la probabilité
d'apparte-
nance à chacun des nb = 3 groupes sous la forme d'une liste de trois valeurs.
On utilisera la
fonction synthese(data,etat) et la fonction gaussienne(a,moy, v).
Sur le patient dont les caractéristiques sont les suivantes : 48,26, 16,42,
36,33, 31,84, 94,88, 28,34,
on obtient les probabilités suivantes : appartenance au groupe 0 : 1,1 - 107!°,
appartenance au groupe
1:7,4-107'%, appartenance au groupe 2 : 5,4 - 107.
La décision de l'appartenance à un groupe particulier est prise en déterminant
le maximum parmi les
probabilités de groupes déterminées.
Q21. Ecrire une fonction prediction, dont vous préciserez les arguments, qui
renvoit le numéro
du groupe auquel appartient un élément z.
Usuellement la méthode naïve bayésienne est utilisée dans un espace
logarithmique ; c'est-à-dire
qu'au lieu de calculer la probabilité d'appartenance à un groupe comme vu
précédemment, on calcule
le logarithme de cette quantité.
Q22. Proposer une explication qui justifie cette utilisation du logarithme.
L'algorithme mis en place peut être testé sur le jeu de 100 données test
utilisé pour l'algorithme KNN
dont on connaît déjà l'appartenance à chacun des groupes. On obtient alors la
matrice de confusion
suivante :
23 9 8
9 10 1!
10 1 49
Q23. Calculer le pourcentage de réussite de la méthode KNN, à partir de la
matrice de confusion
pour K = 8 (page 8), ainsi que celui de la méthode naïve bayésienne à partir de
la matrice
ci-dessus. Discuter de la pertinence de chacune des deux méthodes sur l'exemple
traité.
FIN
11/12
ANNEXE
Rappels des syntaxes en Python
Remarque : sous Python, l'import du module numpy permet de réaliser des
opérations pratiques sur les ta-
bleaux : from numpy import *. Les indices de ces tableaux commencent à 0.
Python
tableau à une dimension
L=[1,2,3] (liste)
v=array([1,2,3]) (vecteur)
accéder à un élément
V[0] renvoie 1 (L[®] également)
ayouter un élément
L.append(5) uniquement sur les listes
tableau à deux dimensions (matrice)
M=array(([1,2,3],[3,4,5]))
accéder à un élément
M[1,2] donne 5
extraire une portion de tableau (2 premières co-
M[:,0:21
lonnes)
extraire la colonne 1 M[:,1]
extraire la ligne 1 M[1,:]
tableau de 0 ( 2 lignes, 3 colonnes)
zeros((2,3))
dimension d'un tableau T de taille (5, j)
T.shape donne [i,j]
produit matrice-vecteur
a = array ([[1,2,31,[4,5,6]1,[17,8,91]1])
b = array([1,2,3])
print(a.dot(b))
>>> array ([14,32,50])
séquence équirépartie quelconque de 0 à 10.1 (ex-
clus) par pas de 0.Ï
arange(®0,160.1,6.1)
définir une chaîne de caractères
mot="Python"
taille d'une chaîne len(mot)
extraire des caractères mot[2:7]
for 1 in range(l0O):
boucle For | |
print(i)
1f (13>3):
condition If print(1)
else :
print("hello")
définir une fonction qui possède un argument et ren-
voie 2 résultats
def f(param):
a = param
b = param+xparam
return a,b
tracé d'une courbe de deux listes de points x et y
plot(x,y)
tracé d'une courbe de trois listes de points x, y et z
gca(projection='3d').plot(x,y,2z)
ajout d'un titre sur les axes d'une figure
xlabel(texte)
ylabel(texte)
ajout d'un titre principe sur une figure
title(texte)
12/12
IMPRIMERIE NATIONALE - 191157 - D'après documents fournis