
CCINP Informatique PSI 2023
| Thème de l'épreuve | Reconnaissance optique de caractères |
| Principaux outils utilisés | codage binaire des entiers, complexité algorithmique, bases de données |
| Mots clefs | binairisation, segmentation, flot maximal, coupure minimale, algorithme d'Edmonds-Karp, optimisation univariée, K plus proches voisins |
| Sujet jumeau | CCINP Informatique PC 2023 |
Corrigé
:👈 gratuite pour tous les corrigés si tu crées un compte
👈 l'accès aux indications de tous les corrigés ne coûte que 1 € ⬅ clique ici
👈 gratuite pour tous les corrigés si tu crées un compte
- - - - - - - - - - - - - - - - - - -
👈 gratuite pour ce corrigé si tu crées un compte
- - - - - -
Énoncé complet
(télécharger le PDF)






















Rapport du jury
(télécharger le PDF)


Énoncé obtenu par reconnaissance optique des caractères
SESSION 2023 PSISIN
CONCOURS
COMMUN
INP
ÉPREUVE MUTUALISÉE AVEC E3A-POLYTECH
ÉPREUVE SPÉCIFIQUE - FILIÈRE PSI
INFORMATIQUE
Durée : 3 heures
N.B. : le candidat attachera la plus grande importance à la clarté, à la
précision et à la concision de la rédaction.
Si un candidat est amené à repérer ce qui peut lui sembler être une erreur
d'énoncé, il le signalera sur sa copie
et devra poursuivre sa composition en expliquant les raisons des initiatives
qu'il a été amené à prendre.
RAPPEL DES CONSIGNES
«_ Utiliser uniquement un Stylo noir ou bleu foncé non effaçable pour la
rédaction de votre composition ; d'autres
couleurs, excepté le vert, peuvent être utilisées, mais exclusivement pour les
schémas et la mise en
évidence des résultats.
. _ Ne pas utiliser de correcteur.
« Écrire le mot FIN à la fin de votre composition.
Les calculatrices sont interdites.
Le sujet est composé de trois parties.
L'épreuve est à traiter en langage Python sauf pour les bases de données.
Les différents algorithmes doivent être rendus dans leur forme définitive sur
le Document
Réponse dans l'espace réservé à cet effet en respectant les éléments de syntaxe
du langage
(les brouillons ne sont pas acceptés).
La réponse ne doit pas se limiter à la rédaction de l'algorithme sans
explication, les pro-
grammes doivent être expliqués et commentés.
Énoncé et Annexe : 16 pages
Document Réponse (DR) : 12 pages
Seul le Document Réponse doit être rendu dans son intégralité.
1/16
Reconnaissance optique de caractères
Introduction
La reconnaissance optique de caractères (OCR) existe depuis de nombreuses
années mais
les récents travaux d'intelligence artificielle (apprentissage profond) ont
considérablement
augmenté les performances de la reconnaissance de documents.
L'objectif du travail proposé est de découvrir différentes étapes de la
numérisation
d'un document en explorant plusieurs algorithmes utilisés pour obtenir au final
un
document éditable conforme à l'original.
Le sujet abordera les points suivants :
- acquisition d'un document et pré-traitement dans le but d'obtenir une image
numérique
pertinente ;
- reconnaissance du contenu qui correspond à l'extraction du texte et de sa
structure ;
- reconnaissance des caractères par identification à l'aide d'une base de
données.
Partie | - Acquisition d'un document
L'acquisition du document est obtenue généralement par balayage optique. Le
résultat est
rangé dans un fichier de points (pixels) dont la taille dépend de la résolution.
Une image en couleurs est stockée dans une matrice imgC de p lignes (pixels en
hauteur), g
colonnes (pixels en largeur) dont chaque élément est un triplet. Chaque valeur
du triplet de
couleur (rouge, vert, bleu) est un entier compris entre 0 et 255. La résolution
est exprimée
en nombre de pixels par pouce (ppp). La valeur d'un pouce est environ égale à
2,5 cm.
Q1. Chaque entier représentant une couleur est représenté, en binaire, sous la
forme d'un
mot constitué de bits 0 et de 1. Donner la taille de ce mot pour qu'il puisse
représenter
tous les entiers compris entre 0 et 255. Indiquer les dimensions (en pixels)
d'une image
en couleurs au format A4 (21 cm x 29,7 cm) pour une résolution de 300 ppp. En
déduire
alors la taille en bits du fichier image correspondant.
Pour diminuer la taille du document afin de pouvoir plus facilement le traiter,
on réalise tout
d'abord une conversion en niveaux de gris de l'image.
L'image en niveau de gris est une matrice imgG à p lignes et qg colonnes où
chaque valeur
est un entier entre 0 (pixel noir) et 255 (pixel blanc).
La formule utilisée pour déterminer la valeur d'un pixel gris en fonction des
trois couleurs
d'un pixel (R rouge, G vert, B bleu) est la suivante : pixGris = 0,299 x R +
0,587 x G +0,114*B.
De manière générale, on nomme le type array pour représenter une matrice sous
la forme
d'une liste de listes dont les éléments de la liste interne pourront être des
triplets pour les
images en couleurs ou des entiers pour les images en niveau de gris.
On introduit les fonctions :
- dimension(img:array) -> tuple qui renvoie le triplet (p, g, 3) pour une image
en cou-
leurs et le triplet (p, q, 1) pour une image en niveau de gris;
- initialise(p:int, q'int, valeur:int) -> array Qui renvoie Une image de dimen-
SIONS (p, q) où tous les pixels sont initialisés à une même valeur valeur.
2116
On donne la fonction permettant de convertir en niveau de gris l'image en
couleurs.
def conversion gris (imgC :array )->array :
n0 ,n1,_ = dimension(imgC)
img = initialise(p,q,0)
for i in range (n0) :
for j in rangel(n1i):
r,g,b = imgCTi]Ti]
val = 0.299 x r + 0.587 x g + 0.114 + b
imgli,j] = int(val)
return img
Q2. Donner la complexité de la fonction conversion gris(imgC:array)->array.
La première étape du prétraitement est la binarisation. Cela consiste à
remplacer les pixels
en niveaux de gris par des pixels noirs (valeur 0) ou blanc (valeur 255)
uniquement. Pour
cela, la valeur du pixel gris est comparée à une valeur seuil notée seuil.
Q3. Proposer une fonction binarisation(imgG:array, seuil:int)->array qui
convertit
une image en niveau de gris en image en noir et blanc en imposant une valeur 255
pour tout pixel de valeur strictement supérieure au seuil.
La difficulté de cette technique de binarisation est le choix de la valeur
seuil pour des images
ayant des problèmes d'éclairage. Nous verrons que la technique de restauration
étudiée par
la suite peut être utilisée pour remplacer la binarisation par seuil standard.
3/16
Partie Il - Reconnaissance du document
11.1 - Rotation de l'image
L'image scannée peut avoir un problème de rotation qu'il convient de corriger
afin d'appliquer
l'algorithme de reconnaissance des caractères (figure 1).
'huées aux
s attripu
| g
nité iste pres st grand: rs
se ° jeur n ces o
alt de
peauté impidit® de ussi long "pour la PIUP mps se VI
jacs natuf 18 d'aiti . géants de o antes: ronnent: sé
Creusés ça et le " eu toyantes ets èrement ni"
aux COY et era
montagne: à aux récit en m leur
ile de fon isme ira e lo
toile yenement qui \es sort isïl e leur
our là rt
men Pr à 'eau au", \erf à
UE urils mérite" : ON
| clat \ , CE g ü
écosystèmes ag, les not
co roi é
S mir \
\e, S0
sr priser
re V
partager:
Figure 1 - Image avec un problème de rotation lors de l'acquisition numérique
Le paramétrage de l'image pour la rotation est donné sur la figure 2. L'image
est de dimen-
sion (p, g) (possède p lignes et 4 colonnes). Pour faire tourner le point de
coordonnées (5, j)
autour du point O centre de l'image d'un angle «, on applique une rotation à
l'aide d'une
matrice de rotation :
n;--p//2\ fcosa sina\fi-p//2
n;-gqg//2}] \-sina cosa/\j-g//2]
On obtient alors un nouveau point de coordonnées (n;, n;).
0 J A; q
0 _--
o ;
Njk------------------ LL LS
LE------------------ ---; a
P .
TVQ
Figure 2 - Paramétrage de l'image pour la rotation
Naïvement, on pourrait penser que pour réaliser la rotation, il suffit de
parcourir chaque pixel
de l'image intiale en lui appliquant la rotation définie précédemment. Mais les
indices étant
des entiers, on se rend compte que certains pixels de la nouvelle image ne sont
jamais cal-
culés (figure 3) et qu'il peut apparaître des problèmes de dépassement de
taille d'image.
4/16
Beauté, hHimpidite, pureté, sérénité.
Figure 3 - Rotation naïve de l'image intiale
L'algorithme de rotation consiste donc, pour chaque pixel de la nouvelle image
de coordon-
nées (n;, n;), à trouver ses coordonnées (1, j) par une rotation d'angle -a
dans l'image initiale.
La position du pixel virtuel ainsi trouvée est en fait un couple de réels (x,
y). Le pixel virtuel
est ainsi entouré de 4 pixels dans l'image initiale dont les abscisses sont
comprises entre
int (x) et int (x) +1 et les ordonnées entre int (y) et int(y)+1 (figure 4).
Figure 4 - Illustration du pixel trouvé entouré des 4 pixels voisins dans
l'image intiale
Pour trouver la valeur du pixel virtuel, on utilise la valeur des 4 pixels
voisins en réalisant une
approximation bilinéaire qui consiste :
- en prenant les deux pixels voisins de la première ligne, à trouver la valeur
du niveau
de gris du pixel virtuel en supposant une évolution linéaire selon la
coordonnée y entre
le pixel de gauche et le pixel de droite ;
- à faire de même en prenant les pixels de la deuxième ligne ;
- enfin en travaillant sur la coordonnée x, à supposer une évolution linéaire
entre les
deux valeurs trouvées aux deux étapes précédentes.
On dispose d'une fonction :
lineaire(x:float, x0O:int, xi:int, pix0O:int, pixi:int)-> float
qui renvoie le flottant val, approximation linéaire au point x des valeurs pix0
prise au point x0
et pixi prise au point xl.
Si les coordonnées du point virtuel (x, y) Se situent en dehors de l'image,
alors la valeur du
pixel sur l'image tournée sera prise de couleur blanche, c'est-à-dire égale à
255.
Q4. Choisir la fonction bilineaire(im:array, x:float, y:float)->int parmiles
quatre
propositions, données dans le DR, permettant de respecter les spécifications.
Q5. Compléter la fonction rotation(im:array, angle:float)->array donnée dans le
DR qui prend en argument une image en niveau de gris et un angle en degré et qui
renvoie une nouvelle image tournée de l'angle angle donné en degré. On veillera
à
initialiser l'image par une image complètement blanche (pixels de valeur 255).
On suppose définie une fonction :
prod matrice vecteur(M: array, v: list) -> list
qui renvoie le vecteur colonne (sous forme de liste) résultat de la
multiplication de la
matrice M par le vecteur colonne v.
9/16
Une manière d'implémenter la fonction lineaire est la suivante :
def lineaire(x
float, x0O:int, x1:int, pix0O :int, pixi:int)-> float :
return (x-x0)x(pix1-pixO )/(x1-x0) + pixO
Il se trouve qu'en pratique, si on utilise des tableaux Numpy pour représenter
les matrices,
on peut être tenté de forcer les entiers à être du type uint8 qui correspond à
un entier non
signé (d'où le « u » pour « unsigned ») stocké sur 8 bits.
Q6. Donner une raison pour laquelle il serait intéressant de se contraindre à 8
bits et ex-
pliquer le gain qu'il pourrait en découler en pratique.
Expliquer quel problème pourrait apparaître en réfléchissant au résultat de la
sous-
traction 18 -- 23 où 18 et 23 sont tous deux des entiers non signés sur 8 bits
et où le
résultat est lui aussi obligatoirement un entier non signé sur 8 bits.
En utilisant une telle structure (où pix0 et pixi sont des entiers de type
uint8), on se retrouve
avec l'image pixellisée de la figure 5, ce qui n'est effectivement pas un
résultat voulu, l'image
attendue étant donnée sur la figure 6. L'angle choisi pour cette rotation n'est
pas la valeur
optimale assurant l'horizontalité du texte.
0
100
200
300
400 +
500
'gouement pour randonnée qui és
| éclat qu'ils méritent,
; Écosystémes fragiles, ces réserves d'eau. qui n'ont dé potentisf que: eur
| magie. sont les miroirs dé nas.belles mohtagnés qu'étetiré piètre n'est ence-
4 reVehué briser. pour otre plus grand borhieur Que nûts vois: Ivitons &
Hartagér.
'Beauté, fmpidité, pireté, sérénité. Lé Rste des Iguatiges âttribuées. aux.
| Tcë näturels d'altitude est ausst longue que'feur nombre est grand.
.! 'Creusés géret fé par fes "géants.de glace" pour Fe plupart, ces joyatx. de:
ta
| Hronfagne, aix coufeuts éhétayantes ak surprenantes, ont longtemps: servi de
: toile de. forict aux récits des conquêtes des someefs-qui fes cauroñhent.
: est l'avénemient:dur tourisme EUR en montagne: et plus-partictilièrement. lens
sortiræ de l'embre: 8t leur dornéra tobt
200 400 600 800
Figure 5 - Problème de pixellisation lors de la rotation
Q
Beauté, limpidité, pureté, sérénité... La liste des louanges attribuées aux
100 - lacs naturels d'altitude est aussi longue que leur nombre est grand.
Creusés cà et là par les "géants de glace" pour la plupart, Ces joyaux de la
montagne, aux couleurs Chatoyantes et surprenantes, on longtemps sérvi de
200 + toile de fond aux récits des conquêtes des sommets qui les couronnent
C'est l'avènement du tourisme en montagne et plus particulièrement l'an-
gouement pour la randonnée qui les sortira de l'ombre et leur donnera tout
300 + l'éclat qu'ils meritent.
Écosystèmes fragiles, ces réserves d'eau qui n'ont de potentiel que leur
nadie. sont les miroirs de nos belles montagnes qu'aucune pierre n est enco-
400 À re venue briser. pour notre plus grand bonheur que nous vous imvitons à
partager.
500 - | | | |
Q 200 400 600 800
Figure 6 - Figure attendue après la rotation
6/16
11.2 - Segmentation
La segmentation consiste à découper l'image en plusieurs éléments de manière à
pouvoir
ensuite traiter chacun des éléments. Il faut dans l'image pouvoir dissocier les
lignes, les mots
puis les lettres. L'idée est de construire la liste du nombre de pixels noirs
par ligne.
On peut ensuite détecter les lignes en sélectionnant les zones où il y a
majoritairement des
pixels blancs, ce qui correspond aux zones sans texte.
On applique ensuite le même principe pour détecter les mots et les lettres en
comptant les
pixels blancs verticalement.
On travaille sur une image binarisée, c'est-à-dire ne contenant que des pixels
blancs (255)
ou des pixels noirs (0).
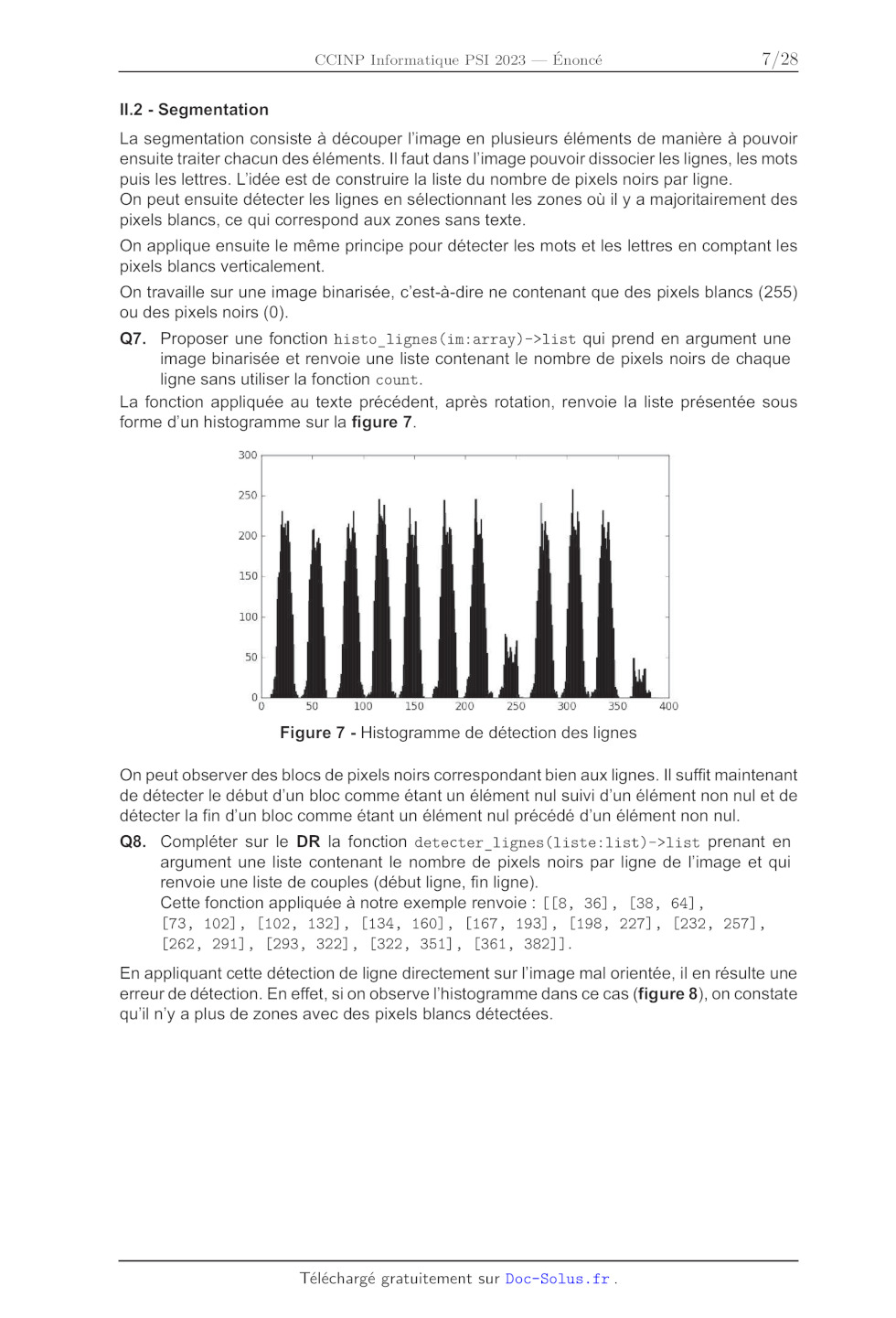
Q7. Proposer une fonction histo lignes(im:array)->list qui prend en argument une
image binarisée et renvoie une liste contenant le nombre de pixels noirs de
chaque
ligne sans utiliser la fonction count.
La fonction appliquée au texte précédent, après rotation, renvoie la liste
présentée sous
forme d'un histogramme sur la figure 7.
300
250 | |
200 | |
150 ! |
100 | |
50 }
0 50 100 150 200 250 300 350 400
Figure 7 - Histogramme de détection des lignes
On peut observer des blocs de pixels noirs correspondant bien aux lignes. Il
suffit maintenant
de détecter le début d'un bloc comme étant un élément nul suivi d'un élément
non nul et de
détecter la fin d'un bloc comme étant un élément nul précédé d'un élément non
nul.
Q8. Compléter sur le DR la fonction detecter lignes(liste:list)->list prenant en
argument une liste contenant le nombre de pixels noirs par ligne de l'image et
qui
renvoie une liste de couples (début ligne, fin ligne).
Cette fonction appliquée à notre exemple renvoie : [[8, 36], [38, 64],
[73, 102], [102, 132], [134, 160], [167, 193], [198, 227], [232, 257],
[262, 291], [293, 3221, [322, 351], [361, 38211].
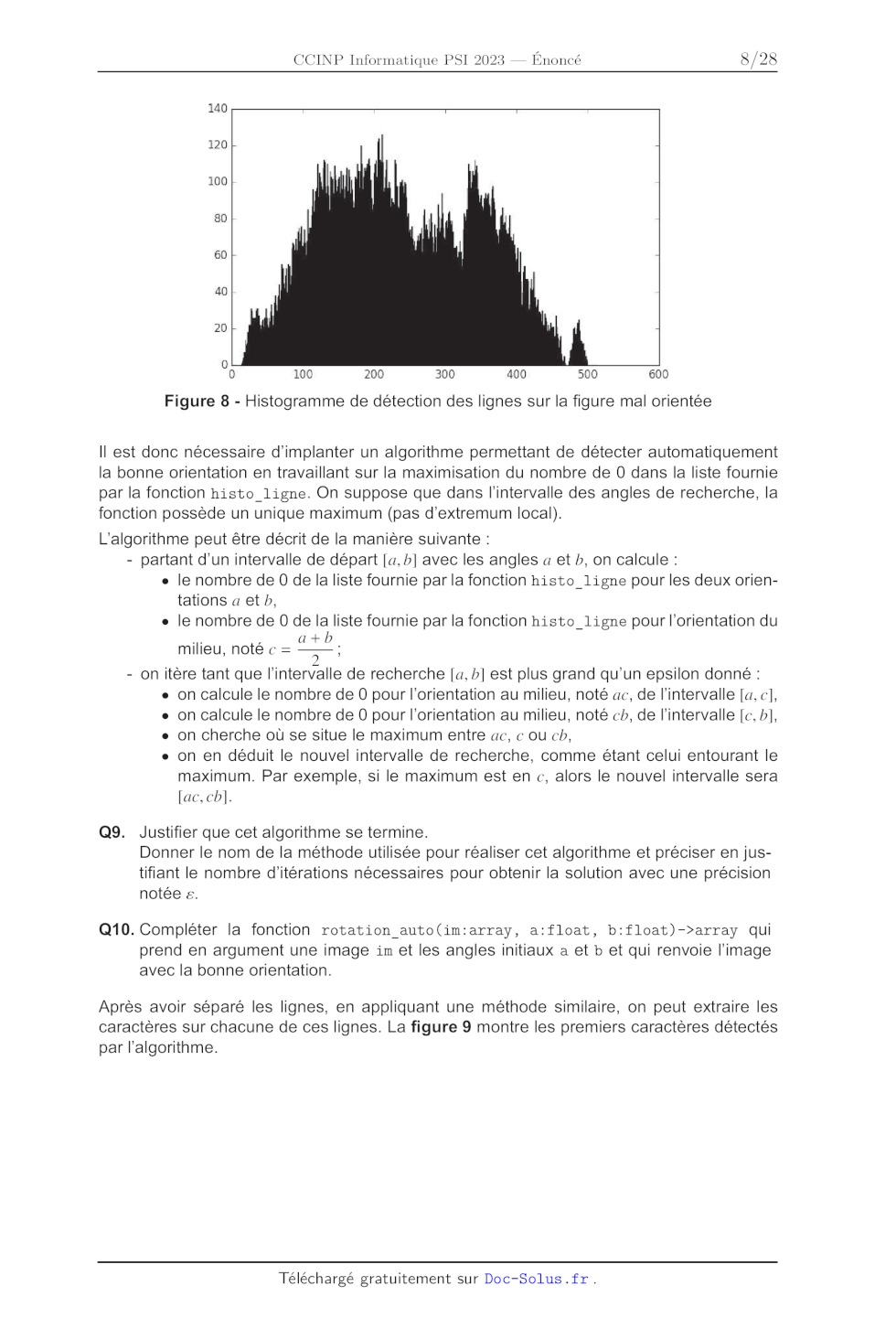
En appliquant cette détection de ligne directement sur l'image mal orientée, il
en résulte une
erreur de détection. En effet, si on observe l'histogramme dans ce cas (figure
8), on constate
qu'il n'y a plus de zones avec des pixels blancs détectées.
716
140 | |
120 E -
100
80
60
40
20
0
(9) 100 200 300 400 200 600
Figure 8 - Histogramme de détection des lignes sur la figure mal orientée
Il est donc nécessaire d'implanter un algorithme permettant de détecter
automatiquement
la bonne orientation en travaillant sur la maximisation du nombre de 0 dans la
liste fournie
par la fonction histo_ ligne. On suppose que dans l'intervalle des angles de
recherche, la
fonction possède un unique maximum (pas d'extremum local).
L'algorithme peut être décrit de la manière suivante :
- partant d'un intervalle de départ [a, b] avec les angles a et b, on calcule :
e le nombre de 0 de la liste fournie par la fonction histo_ ligne pour les deux
orien-
tations a et b,
e le nombre de 0 de la liste fournie par la fonction histo_ ligne pour
l'orientation du
.... , a + b
milieu, noté c = 5
- onitère tant que l'intervalle de recherche {a, b] est plus grand qu'un
epsilon donné :
e on calcule le nombre de 0 pour l'orientation au milieu, noté ac, de
l'intervalle [a, c],
e on calcule le nombre de 0 pour l'orientation au milieu, noté cb, de
l'intervalle [c, b],
e on cherche où se situe le maximum entre ac, c où cb,
e on en déduit le nouvel intervalle de recherche, comme étant celui entourant le
maximum. Par exemple, si le maximum est en c, alors le nouvel intervalle sera
[ac, cb].
Q9. Justifier que cet algorithme se termine.
Donner le nom de la méthode utilisée pour réaliser cet algorithme et préciser
en jus-
tifiant le nombre d'itérations nécessaires pour obtenir la solution avec une
précision
notée &.
Q10. Compléter la fonction rotation auto(im:array, a:float, b:float)->array qui
prend en argument une image in et les angles initiaux a et b et qui renvoie
l'image
avec la bonne orientation.
Après avoir séparé les lignes, en appliquant une méthode similaire, on peut
extraire les
caractères sur chacune de ces lignes. La figure 9 montre les premiers
caractères détectés
par l'algorithme.
8/16
B e a U t e :
Figure 9 - Premiers caractères détectés par l'algorithme
11.3 - Restauration d'image
Les images de caractères peuvent être bruitées compte tenu d'une mauvaise
résolution ou
de parasites apparaissant pendant un scan. De même, la technique de
binarisation proposée
initialement ne donne pas toujours un résultat correct si le seuil est mal
choisi.
La méthode du flot maximal (ou méthode de la coupe minimale) reposant sur la
représenta-
tion par un graphe de l'image à restaurer est souvent utilisée pour pallier ces
problèmes.
La librairie maxf low disponible sous Python propose des fonctions déjà
existantes pour traiter
une image bruitée.
La fonction globale de traitement de l'image est la suivante :
import numpy
import maxflow
def graph cut(img :array)->array :
img = numpy.array(img) #Conversion en array de Numpy pour un usage
plus facile ensuite
g = maxflow.Graphlint]() #création du graphe
nodeids = g.add grid nodes(dimension(img))
g.add grid edges(nodeids, 5)
g.add grid tedges(nodeids, img, 255-img)
g.maxflow ()
sgm = g.get grid segments(nodeids)
img2 = numpy.int _(numpy.logical not(sgm))
return img2
L'objet des questions de cette sous-partie est de comprendre chaque ligne de
cette fonction
et d'illustrer la méthode sur un exemple basique d'une image test (3x3)
constituée de 9 pixels
en niveau de gris (pixels compris entre 0 (noir) et 255 (blanc)).
OR 2 : 210 3 : 190
4 : 20 SMI00.K EU
ROC 9 : 255
Figure 10 - Exemple d'image à restaurer
Les valeurs des pixels de l'exemple sont les suivantes :
[ [ 0, 210, 190 ],
[ 20, 100, 200 ],
[ 10,5, 25 ]]
9/16
La méthode utilise la représentation par graphe pondéré constitué de nr sommets
et "m arêtes.
Chaque sommet correspond à un pixel de l'image. nodeids est donc l'ensemble des
som-
mets du graphe correspondant à l'image de taille dimension(img).
Les arêtes reliant deux sommets sont ensuite construites à l'aide de
l'instruction
g.add grid edges(nodeids, 5) entre un sommet et ses potentiels 4 voisins
adjacents. À
chaque arête e reliant deux sommets, un poids w(e) de valeur fixe 5 est
associé. Cette pon-
dération va représenter la capacité maximale du flot définie par la suite.
Q11. Représenter le graphe correspondant à l'image de (3x3) pixels en précisant
sur
chaque arête la capacité maximale de 5.
Pour mettre en place la méthode de flot maximal, il est nécessaire d'introduire
deux som-
mets supplémentaires (appelés source S et puits P) qui sont reliés par des
arêtes à tous
les sommets précédents. Sur chaque arête entre le sommet S et les sommets
"pixels" on
utilise les valeurs des pixels comme poids, et sur les arêtes entre les sommets
"pixels" et
le sommet P on utilise le complément à 255 des valeurs des pixels. C'est le
rôle de la ligne
g.add grid tedges(nodeids, img, 255-img).
Q12. Compléter sur le DR la partie supérieure de la matrice de capacités
correspondant au
graphe complet de l'exemple en prenant l'ordre suivant pour les sommets : S, 1,
2,..,
9, P avec pour valeurs les poids précédemment introduits pour chaque arête. Le
poids
est nul si le sommet i n'est pas relié au sommet j.
La fonction g.maxflow() calcule le flot maximal, ce qui permettra par la suite
de partitionner
les sommets.
Le flot est une notion similaire à un flux de fluide qui s'écoulerait de la
source vers le puits.
Mathématiquement, le flot est une fonction f définie de l'ensemble des arêtes e
EUR E vers
l'ensemble des réels KR. Cette fonction vérifie les propriétés suivantes :
- Ve =(p,g)e E (avec p,q deux sommets), f(p, q) = ---f(a, p), le flot dans le
sens q vers
p est l'opposé du flot dans le sens p vers g;
- pour tout sommet p autre que S et P: > f(e) = 0, la somme des flots arrivant
et
e=(p,.)EURE
sortant d'un sommet est nulle, ce qui est similaire à la loi de Kirchoff;
- pour toute arêteee E, f(e) < w(e), le flot ne peut pas dépasser la capacité maximale définie initialement. On pourrait définir une matrice de flots similaire à la matrice de capacités qui contiendrait les valeurs des flots au lieu des capacités. On passe du graphe non orienté que nous venons de décrire à un graphe orienté. Les arêtes faisant intervenir la source sont alors orientées de la source vers les sommets (flot sortant de la source); celles faisant intervenir le puits sont orientées des sommets vers le puits (flot entrant dans le puits); les arêtes entre des sommets : et j correspondant à des pixels sont dédoublées (une de i vers j, l'autre de j vers i) et ont chacune une capacité maximale égale à 5. La figure 11 montre un exemple de flot sur une partie seulement du graphe de l'exemple étudié. Les étiquettes de la forme i/j représentent pour i la valeur du flot et pour j la valeur de la capacité maximale. Le flot est maximal lorsque les flots partant de la source S sont maximaux tout en respectant toutes les règles précédentes. On dit qu'une arête est saturée lorsque le flot de cette arête est égal à sa capacité. 10/16 Figure 11 - Exemple d'extrait de graphe avec flot Pour déterminer le flot maximal, une méthode possible consiste à saturer des arêtes. Pour cela, on utilise un graphe complémentaire appelé graphe résiduel, obtenu à partir du graphe de flot sur lequel on indique sur chaque arête e EUR E la capacité résiduelle (dans un sens et dans l'autre) : r(e) = w(e) -- f(e). Si une arête est étiquetée 0 sur le graphe résiduel, alors il n'est plus possible d'emprunter cette arête pour construire le chemin de longueur minimal. La figure 12 montre le graphe résiduel associé au graphe avec flot de la figure 11. Figure 12 - Exemple de graphe résiduel On utilise l'algorithme d'Edmonds-Karp : à partir du flot nul, on cherche itérativement un plus court chemin EUR (c'est-à-dire un chemin où la somme des étiquettes du graphe résiduel en parcourant les arêtes le constituant est minimal et comportant le moins d'arêtes) de la source au puits sur lequel il n'y a pas d'arête saturée (c'est-à-dire un chemin pour lequel aucune des arêtes correspondantes du graphe résiduel n'est pondérée par 0). On rajoute alors autant de flots que possible à ce chemin (c'est-à-dire on sature l'arête qui a une capacité résiduelle minimale). L'algorithme de recherche du flot maximal est le suivant en pseudo-code : Initialisation : poser f(e) = O0 pour toute arête e définir le graphe résiduel initial définir un chemin C de S à P dans le graphe résiduel de longueur minimale tant qu il existe un chemin C de S à P dans le graphe résiduel faire prendre un chemin C de longueur minimale a = min(r(e)| e dans C) pour tout e dans C faire f(e) = f(e) +a fin pour mettre à jour Île graphe résiduel fin tant que 11/16 Q13. Appliquer cet algorithme sur les graphes du DR en précisant à chaque étape le che- min choisi et la valeur de l'augmentation du flot jusqu'à sa terminaison. Le graphe de gauche représente le graphe de flot et le graphe de droite le graphe résiduel. On donne le graphe initial avec un flot nul ainsi que le graphe résiduel associé. Pour transformer l'image en niveau de gris en une image noir et blanc, c'est-à-dire pour séparer les pixels entre ceux qui prennent la valeur 0 et ceux qui prennent la valeur 255, on va réaliser une coupe dans le graphe des pixels. On définit l'ensemble À contenant la source S et certains sommets ainsi que l'ensemble B contenant le puits P et les sommets restants. La capacité de la coupe est la somme des capacités des arcs orientés de A vers B. Par exemple, supposons que nous ayons coupé le graphe entre les ensembles À = {S, 1, 2} et B = {P, 4}. En sommant les capacités maximales des arêtes orientées allant d'un sommet de À vers un sommet de B, on obtient une capacité de coupe de 20+5+255+45 = 325. Figure 13 - Coupe dans un graphe L'algorithme d'Edmonds-Karp permet de construire un flot maximum, c'est-à-dire un flot dont la somme des arêtes arrivant au puits est maximale. Le théorème du " flot maximal et coupe minimale " assure que la valeur de ce flot maximal est égale à la valeur de coupe minimale. Pour réaliser cette coupe, on met dans l'ensemble A la source S et tous les sommets ac- cessibles, depuis S, par des arêtes non saturées; on met dans l'ensemble B les sommets restants. L'appel g.get_ grid segments (nodeids) renvoie une liste indiquant, pour chacun des som- mets, sil appartient ou non au même ensemble que la source. Q14. Dans l'exemple précédent, indiquer les deux ensembles À et B en précisant la valeur du flot maximal et en vérifiant que la capacité de coupe réalisée correspond bien à une valeur égale à celle du flot maximal. Lorsqu'on applique la fonction précédente sur l'image d'un caractère, on obtient la nouvelle image de la figure 14. Figure 14 - Caractère scanné et caractère après traitement par la fonction graph_cut Q15. Indiquer pour cette image de la figure 14 à quoi correspondent les ensembles A et B. Analyser le résultat obtenu. 12716 Partie III - Détermination des caractères Une fois les images de lettres isolées, il s'agit de reconnaître la lettre correspondante. Diffé- rentes méthodes peuvent être employées. Nous allons étudier une méthode d'apprentissage automatique basée sur les K plus proches voisins. Le principe de cette méthode consiste à comparer chaque caractère à un ensemble de ca- ractères définis dans une base de données. 11.1 - Analyse de la base de données de caractères La base de données contient des informations sur chaque caractère selon le type de fonte, la taille, la graisse... Trois tables sont utilisées. ' FONTES | SYMBOLES | CARACTERES id d Id nom label id_symbole famille catégorie id_fo nie taille fichier graisse | ° style La table SYMBOLES contient les attributs suivants : - id : identifiant d'un symbole (entier), clé primaire ; - label : nom du symbole (A, a", "1", 6", !" .....) (chaîne de caractères); - catégorie : parmi majuscule, minuscule, chiffre, spécial (dont accent) (chaîne de ca- ractères). La table CARACTERES contient les attributs suivants : - id : identifiant d'un caractère (entier), clé primaire ; - id symbole : identifiant du nom du symbole (entier); - id fonte : identifiant du type de fonte (entier); - fichier : nom du fichier image correspondant (chaîne de caractères). La table FONTES contient les attributs suivants : - id : identifiant d'une fonte (entier), clé primaire ; - nom : nom de la fonte ("Arial'",'"Times new roman", "Calibri","Zurich",....)(chaîne de caractères); - famille : nom de la famille dont fait partie la fonte ("humane", "garalde", "réale"!, "didone", "scripte", ...) (chaîne de caractères); - taille : dimension en hauteur des caractères en pixels (entier); - graisse : type de graisse ("léger", "normal", "gras", "noir", ...) (chaîne de carac- tères); - Style : type de style ("romain", "italique", "ombré", "décoratif", ...) (chaîne de ca- ractères). Q16. Écrire une requête SQL permettant d'extraire les identifiants des fontes dont le nom est "Zurich", de style "romain" et dont la taille est comprise entre 10 et 16 pixels. Q17. Écrire une requête SQL permettant d'extraire tous les noms de fichiers des caractères qui correspondent au symbole de label "A". Q18. Écrire une requête SQL permettant d'indiquer le nombre de caractères correspondant à la fonte "Zurich", de style "romain" et dont la taille est comprise entre 10 et 16 pixels groupés selon les labels des symboles. 13/16 II1.2 - Classification automatique des caractères Dans la suite du sujet, on suppose qu'on dispose d'une liste fichiers car _ ref contenant les noms des fichiers images d'un grand nombre de caractères ayant des fontes proches de celles du texte scanné. Le nom de chaque fichier est défini de la manière suivante : nomFonte + "_" + nomCatégoriettaillePolice + " " + idSymbole + ".png" Les catégories sont définies par la liste : categories = ['majuscules" ,'"minuscules" ,"chiffres" ,"special"]. Les symboles considérés sont définis par la liste : symboles = [''ABCDEFGHIJKLMNOPQRSTUVWXYZ" ,""abcdefghi jklmnopqrstuvwxyz", "0123456789" ,".:,;'(1?)éèàcüêüâ"]. On compte 7/9 symboles différents. Exemple : Zurich Light BT majuscules18_10.png pour la majuscule K de la police Zurich Light BT en taille 18. On introduit la fonction suivante : def lire symbole fichier(nomFichier :str)->str :
car nomFichier.split("_)
num = car[2].split(". )[0]
var car[1][:len(car[1])-2]
ind categories.index(var)
return symboles![ind]f[int(num)]
Pour une liste L, L.index(val) renvoie la position de val dans la liste L.
Q19. Indiquer ce que valent les variables car, num, var, ind et ce qui est
renvoyé par la
fonction SinomFichier="Zurich Light BT majuscules18 10.png".
Toutes les images des caractères de référence sont lues et stockées sous forme
de tableaux
array. On définit un dictionnaire carac_ref dont les clés seront les symboles
apparaissant
dans la liste symboles (par exemple "A", "a", .....). À chaque clé sera
associée une liste de
tableaux array représentant des images.
La commande img=imread(nomFichier) permet de lire le fichier image nomFichier
et de
stocker le tableau array à deux dimensions qui représente l'image dans la
variable img.
Q20. Écrire une fonction lire donnees ref(fichiers car ref:list)->dict qui
prend en
argument la liste des noms de fichiers images fichiers car ref et qui renvoie le
dictionnaire contenant tous les tableaux catégorisés.
Un caractère à identifier est également stocké sous forme d'un tableau array
nommé
carac_test. On suppose que les dimensions de ce tableau et de tous les tableaux
du dic-
tionnaire carac_ref sont les mêmes.
La méthode d'identification utilisée est celle des K plus proches voisins. Elle
consiste à cal-
culer une distance entre l'image du caractère à identifier et toutes les images
de référence.
En notant (i, j) les coordonnées d'un pixel dans le tableau représentant
l'image, p;; le pixel
associé à l'image du caractère à identifier et g;; celui d'un caractère de
référence, on calcule
pour chaque caractère de référence la distance d = VE -- qi; .
Les distances 4 sont stockées dans un dictionnaire distances où, pour chaque
clé égale à
un symbole de la liste symboles, on associe une liste de distances pour chaque
image de
référence de ce symbole.
Q21. Écrire une fonction distance(imi:array, im2:array)->float qui calcule la
distance
entre les deux images imi et im2 supposées de même dimension.
14/16
Q22. Écrire une fonction calcul _distances(carac ref:dict, carac
test:array)->dict
qui prend en argument le dictionnaire des tableaux catégorisés et un tableau
associé
au caractère à tester et qui renvoie le dictionnaire des distances.
La suite consiste à déterminer les K plus petites distances et extraire les
clés correspon-
dantes, puis parmi ces clés déterminer la clé majoritaire. Une méthode
envisageable est de
trier les distances par ordre croissant pour prendre les K premiers éléments.
On suppose
qu'il y a au total n images de caractères de référence sur l'ensemble des
symboles.
Q23. En se plaçant dans le pire des cas, indiquer le nom d'une méthode de tri
performante
envisageable, en précisant sa complexité temporelle en fonction de n.
Une méthode plus efficace est envisagée pour extraire directement les K plus
petits élé-
ments. Elle consiste à construire par tri par insertion la liste de taille K.
L'algorithme corres-
pondant est donné dans le DR.
Q24. Compléter les 3 zones manquantes dans cet algorithme.
Q25. Préciser la complexité temporelle asymptotique dans le pire des cas de cet
algorithme
en fonction de n et de K. Comparer avec l'utilisation d'un tri classique
sachant que n
est grand et K ne dépassera pas 5.
Q26. Écrire une fonction symbole majoritaire(voisins:1ist)->str qui à partir de
la liste
voisins renvoyée par la fonction Kvoisins renvoie le symbole majoritaire.
On teste l'algorithme sur les caractères extraits dans la partie précédente
("Beauté , ").
On obtient les résultats suivants.
Nombre de | Type d'éléments dans la base de set Caractères
.. , Nombre d'éléments dans la base n
voisins K données obtenus
ee , /9 images correspondant aux 79 |
1 fonte similaire au texte analysé "Bssi!l-,"
symboles
4 fonte similaire au texte analysé 79 images correspondant aux 79 "Bssi!-,"
symboles
40 fontes proches de celle du texte | 40*79 images correspondant aux |
1 , "Bsauté ,"
analysé 79 symboles
40 fontes proches de celle du texte | 40*79 images correspondant aux |
4 , "Bsauté ,"
analysé 79 symboles
1 40 fontes pour 8 polices différentes 320°79 images correspondant aux "Beauté,"
79 symboles
4 40 fontes pour 8 polices différentes 32079 images correspondant aux "Beauté,"
79 symboles
Q27. Commenter les résultats obtenus.
15/16
ANNEXE
Rappels des syntaxes en Python
Fonctionnalités
Python
détermination du nombre de zéros dans la liste x
X.count (0)
définir une chaîne de caractères
mot = 'Python'
taille d'une chaîne len(mot)
extraire des caractères (avec le même fonctionne-
ment des indices que pour les extractions de sous- | mot [2:7]
listes)
éliminer le \n en fin d'une ligne
ligne.strip()
découper une chaîne de caractères selon un carac-
tère passé en argument. On obtient une liste qui
contient les caractères séparés.
Dans l'exemple ci-contre, on découpe à chaque oc-
39 9
currence du caractère ",
mot.split(',')
ouverture d'un fichier en lecture et lecture des don-
nées (data est une liste de chaînes de caractères
dont la taille est le nombre de lignes du fichier lu)
with open('nom_ fichier','r') as f:
data = f.readlines()
FIN
16/16
NATIONALE - 231143 - D'après documents fournis
IMPRIMERIE
Numéro N
d'inscription
C COMMUN Nom :
| IN Numéro
de table
Prénom :
Née) le
Filière: PSI
Session: 2023
Épreuve de: INFORMATIQUE
Emplacement
QR Code
Consignes
+ Remplir soigneusement l'en-tête de chaque feuille avant de commencer à
composer
+ Rédiger avec un stylo non effaçable bleu ou noir
. Ne rien écrire dans les marges (gauche et droite)
+. Numéroter chaque page (cadre en bas à droite)
* Placer les feuilles A3 ouvertes, dans le même sens et dans l'ordre
PSISIN
DOCUMENT REPONSE
Ce Document Réponse doit être rendu dans son intégralité.
Q1 - Taille du mot en bits. Dimensions en pixels d'une image. Taille en bits du
fichier i e
Q2 - Complexité de la fonction conversion gris( -array)->arra
1/12
NE RIEN ÉCRIRE DANS CE CADRE
Q3 - Fonction binarisation( :array, seuil:int)->arra
Q4 - Choix de la fonction bilineaire(im:array, x:float, y:float)->int
def bilineaire(im:array ,x:float ,y:float)->int :
x0O = int(x)
x1 = x0+1
yO = int(y)
y1 = y0+1
a = lineaire(y,y0,y1,im[x0][y0],imf[x1][y1l])
b = lineaire(y,y0,y1,im[x1][y0],im[x0][y1])
c = lineaire(x,x0,x1,a,b)
return int(c)
def bilineaire(im:array ,x:float ,y:float)->int :
x0O = int(x)
x1 = x0+1
yO = int(y)
y1 = y0+1
a = lineaire(y,y0,y1,im[x0][y0],im[x0][y1])
b = lineaire(y,y0,y1,im[x0][y0],im[x1][y0])
c = lineaire(x,x0,y1,a,b)
return int(c)
def bilineaire(im:array ,x:float ,y :float)->int :
x0O = int(x)
x1 = x0+1
yO = int(y)
y1 = yO+1
a = lineaire(y,y0,y1,im[x0][y0],im[x0][y1])
b = lineaire(y,y0,y1,im[x1][y0],im[x1][y1])
c = lineaire(x,x0,x1,a,b)
return int(c)
def bilineaire(im:array ,x:float ,y :float)->int :
x0O = int(x)
x1 = x0+1
yO = int(y)
y1 = yO+1
a = lineaire(y,y0,y1,im[x0][y0],im[x0][y1l])
b = lineaire(y,y0,y1,im[x1][y0],im[x0][y1])
c = lineaire(y,y0,y1,a,b)
return int(c)
2112
Q5 - Fonction rotation(im:array, angle:float)->array
def rotation(im:array, angle 'float )->array :
p,q,_ = dimension(im)
IMr = ......................
angr = .....................:
matR = ......................
for ni in range(...................... ) :
for nj in range(...................... ) :
X, YV = ...............,44 44444 eee dede.
X = X + ............
Y = YV + ............
Df _.........................,.,.,.....0
return imr
- Étude de la fonction lineaire
Q7 - Fonction histo_ lignes(im:array)->list
3/12
Q8 - Fonction detecter lignes(liste:list)->list
def detecter lignes(liste :list)->list :
lignes = {]
| = 0
deb = -1 #contient -1 tant qu on parcourt des lignes de pixel blanc
while ...................
elif .............................
return lignes
- Justification de la terminaison et nom de la méthode. Nombre d'itérations
nécessaires
4/12
Numéro N
d'inscription
CONCOURS
C COMMUN Nom :
Numéro
de table
Prénom :
Née) le
Filière: PSI Session: 2023
Épreuve de: INFORMATIQUE
+ Remplir soigneusement l'en-tête de chaque feuille avant de commencer à
composer
+ Rédiger avec un stylo non effaçable bleu ou noir
Consignes ° Ne rien écrire dans les marges (gauche et droite)
+. Numéroter chaque page (cadre en bas à droite)
* Placer les feuilles A3 ouvertes, dans le même sens et dans l'ordre
Emplacement
GR Code
PSISIN
Q10 - Fonction rotation auto(im:array, a:float, b:float)->array
def nb _zeros(im :array, angle 'float )->int :
imr = rotation(im, angle)
ligne = histo lignelimr)
f=ligne.count(0)
return f
def rotation auto(im:array, a:float, b:float)->array:
c = (a+b)/2
fc = nb zeros(im,c)
while b-a > 0.1:#plus grand que 0.1 degré
AC = .............
fac = ............
CD = .............
fcb = ............
maxi = max(fac ,fc ,fcb)
If ............. == maxi
b = c
C = ac
fc = fac
elif ............. == maxi :
a = ac
b = cb
else :
A = .............
C = .............
fC = .............
return rotation(im,(b+a)/2)
(c) 9/12
NE RIEN ÉCRIRE DANS CE CADRE
Q11 - Graphe de l'exemple de taille 3x3
Q12 - Compléter la partie supérieure de la matrice de capacités
S 1 2 3 À 5 6 1 8 9 P
DUO MN D OR © N
l
l
l
l
l
l
6/12
Q13 - Compléter les graphes de flot à gauche et résiduel à droite. Pour chaque
étape, pré-
ciser le chemin choisi et la valeur de l'augmentation du flot
Q14 - Ensembles À et B. Flot maximal. Coupe choisie et capacité de coupe
Q15 - Correspondance ensembles A et B. Ana
7112
Q16 - Requête SQL
Q17 - Requête SQL
Q18 - Requête SQL
Q19 - Contenu des variables car, num, var, ind. Retour de la fonction
Car : Var :
num : ind :
Retour de la fonction :
8/12
Numéro
d'inscription
CONCOURS
C COMMUN Nom :
| IN Numéro
de table
Prénom :
Née) le
Session: 2023
Épreuve de: INFORMATIQUE
Emplacement
QR Code
+ Remplir soigneusement l'en-tête de chaque feuille avant de commencer à
composer
+ Rédiger avec un stylo non effaçable bleu ou noir
. Ne rien écrire dans les marges (gauche et droite)
+. Numéroter chaque page (cadre en bas à droite)
* Placer les feuilles A3 ouvertes, dans le même sens et dans l'ordre
Consignes
Q20 - Fonction lire donnees ref(fichier car ref:list)->dict
PSISIN
Q21 - Fonction distance(imi:array, im2:array)->float
9/12
NE RIEN ÉCRIRE DANS CE CADRE
Q22 - Fonction calcul distances(carac ref:dict, carac test:array)->dict
Q23 - Méthode de tri performante envisageable et complexité temporelle
Q24 - Compléter les 3 zones manquantes
def Kvoisins (distances :dict ,K:int)->list :
voisins = [(float("inf"), ) for K in range(K)|
for lettre in distances :
d = distances![lettre]
for j in range( ............... ) :
Pf ..........................
Kk = len(voisins )-1
While ...............................
voisins[k] = voisins[k-1]
K = kK -- 1
voisins[k] = [dfj], lettre]
return voisins
10/12
Q25 - Complexité en fonction de n et K. Comparaison
Q26 - Fonction s
bole majoritaire(voisins:list)->str
11/12
7 - Commentaires
FIN
12/12